




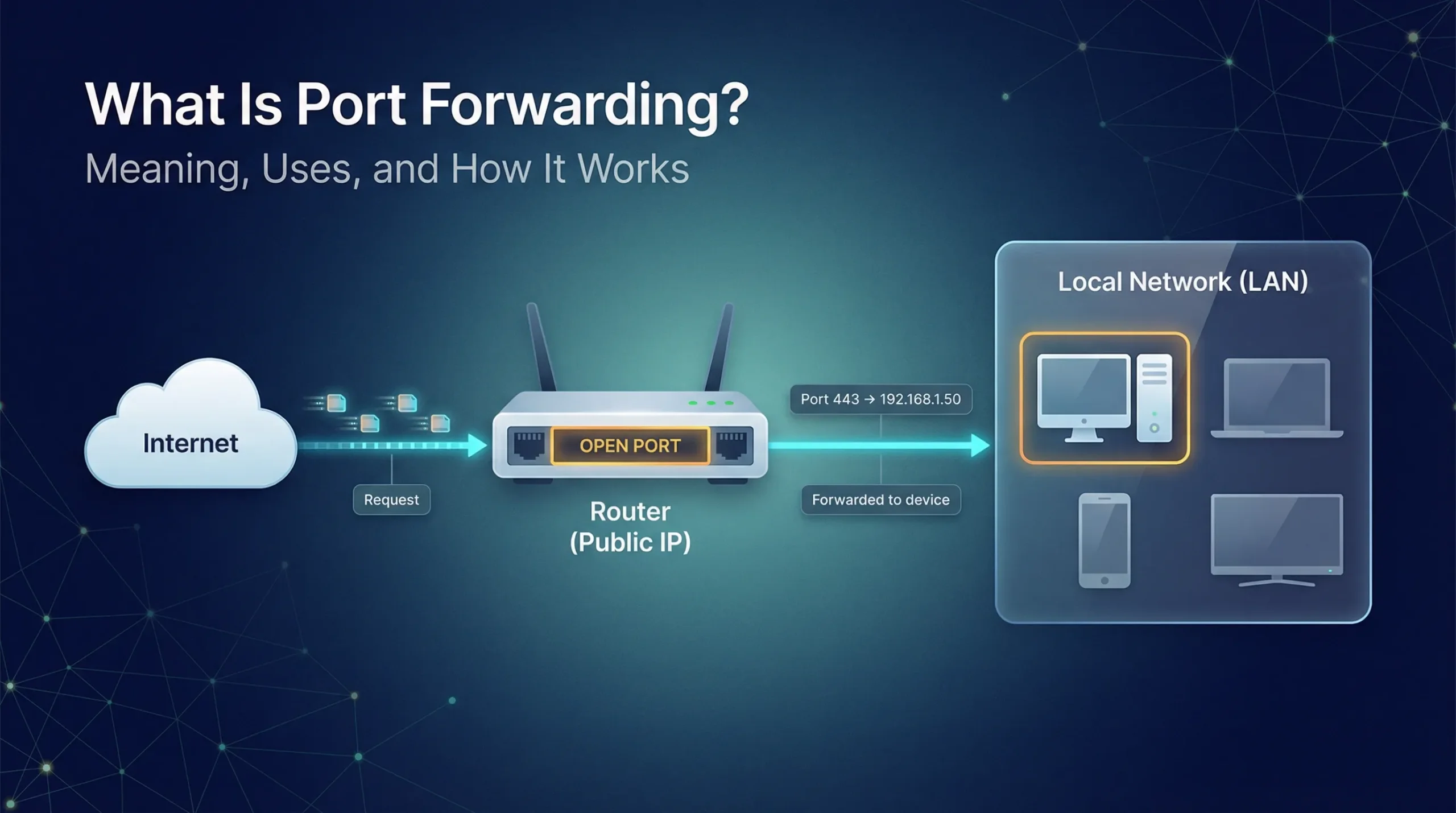


Network redundancy means having extra or duplicate parts in a network so it keeps on working even if something breaks. It is basically a backup path. If one cable, switch, or server fails, the network uses another route. This matters because hardware failure can occur due to power issues or because of physical damage to the equipment, as well as simple wear. With redundancy, the network stays up, thus reducing downtime. Since many people confuse related terms, it helps to see how redundancy connects to fault tolerance and high availability.
Fault Tolerance vs High Availability
Fault tolerance lets a system keep running without any pause because a fully active backup is already in place. However, High Availability uses backups as well, but focuses on quick recovery rather than instant switching. Fault Tolerance aims for zero interruption, while high availability aims for very little downtime but both depend on redundancy.
How Redundancy Prevents Single Points of Failure
A single point of failure is one part that can bring the whole network down if it stops working. Redundancy removes this risk by adding backup paths or devices. Because there is always another route, one failure does not stop the entire system. Thus, redundancy makes the network more stable, reliable, and ready for unexpected issues.
Why Network Redundancy Is Critical in 2026
With the increased prevalence of cloud services for businesses, 2026 provides an even greater need for ensuring continued connectivity. Today’s companies are using cloud services, and these services must stay online for work to continue; if there is any interruption to the network, cloud tools stop working, and teams cannot access files or apps.
Since hybrid and remote work are now normal, people rely on stable connections from many different locations. A single network failure can pause whole teams, thus slowing down projects and customer support.
Companies have a greater reliance on mission-critical applications than before. These tools handle payments, production, data processing, and customer operations. If they go down even for a short time, the impact can be a lot bigger.
With the increase in the prevalence of cyber threats, attacks can overload or disrupt networks, but redundancy helps traffic shift to safer paths, thereby keeping services running while the issue is handled.
IoT and edge devices add even more pressure. These devices need steady connections to send data in real time. When they fail, important processes may stop or become unsafe.
Because downtime costs keep getting higher every year, which means businesses cannot afford long outages. A redundant network reduces this risk by making operations run smoothly and by protecting both revenue as well as reputation.
Core Components of a Redundant Network Architecture
A redundant network is built by adding extra parts that can take over when something fails. This includes using duplicate hardware like switches, routers, and firewalls, so even if one device goes down, the rest of the network will continue functioning. It also uses redundant links, such as multiple fiber lines, Ethernet connections, wireless paths, or even more than one internet carrier.
The importance of failover protocols is quite high as well. HSRP, VRRP, and STP variants help the network switch to a backup path automatically when the primary path fails. The backup power systems (UPS units/Generators/Dual Power Supplies) keep equipment running during power outages. Load balancing and clustering distribute the traffic among several devices, putting less strain on the devices and increasing their reliability.
Physical Redundancy: Devices and Cabling
Physical redundancy means having extra hardware and cables. This can include using two switches instead of one, running multiple fiber lines, or placing devices in separate rooms or racks. Because there is more than one physical path, the network can keep working even if a cable breaks or a device fails.
Logical Redundancy: Protocols and Failover Mechanisms
Logical redundancy uses both software and protocols to detect failures and switch traffic to backup routes. Protocols like HSRP and VRRP help routers take over for each other, while STP variants prevent loops and keep paths stable. These tools make the network react quickly, therefore also reducing downtime at the same time.
Power and Environmental Redundancy
Power redundancy protects the network when electricity fails. UPS systems give short-term power, generators provide longer support, and dual power supplies provide a backup in the event of a power failure from either source. Similarly, environmental redundancy also matters; cooling systems, proper airflow, and separate power circuits help prevent overheating and/or electrical issues, thereby keeping the network stable.
Best Practices to Implement Redundancy in 2026
- Determine where the weak spots are by identifying the areas that have a single point of failure.
- Diversify routing and make use of dual connections to ensure there is always another route available for traffic.
- Make sure that failover designs are easy and effective to ensure that switching is fast and dependable.
- Test failovers on a regular basis to ensure that backups are actually functioning as required.
- Continuously monitor redundant links to be aware of issues in advance and prevent hidden failures.
- Document network diagrams and SOPs so teams know how everything is built as well as managed.
- Keep all backup configurations up-to-date to ensure devices can take over smoothly.
Challenges and Trade-Offs of Network Redundancy
- Hardware and maintenance add cost, which may not be achievable for all teams.
- The added complexity of managing multiple paths requires skilled staff.
- Misconfigurations can create loops or instability, causing more problems than they solve.
- Over-engineering of the network can also make it harder to manage and more expensive than necessary.
- In addition, continuous monitoring is needed to make sure backups stay healthy.
Business Impact & ROI of Proper Redundancy
- Proper redundancy reduces downtime costs by keeping systems running even when something fails.
- It increases customer satisfaction because services stay available and users experience fewer disruptions.
- It improves operational stability by preventing sudden outages that slow down work.
- It supports better scalability since a strong, stable network can handle new tools and systems more easily.
- It helps with compliance and risk management because many industries require reliable, always-on networks.
Common Mistakes When Designing Network Redundancy
- Some teams add too much redundancy, which makes the network more complex than it needs to be.
- Many systems fail because the failover process is never tested in real situations.
- Documentation is often ignored, making it hard to understand how backups are supposed to work.
- Backup paths are not monitored, so they fail silently and are useless during an outage.
- Using only one ISP or carrier creates a single point of failure even if the internal network is redundant.
- Power redundancy is sometimes forgotten, leaving devices vulnerable during power issues.
FAQs
1. What does network redundancy mean?
Network redundancy means having backup devices or paths so the network keeps working if something fails. It helps prevent downtime and keeps users connected without interruption.
2. Why is redundancy important in 2026?
More cloud use, remote work, and connected devices make networks more sensitive to failures. Redundancy keeps systems stable even as demands and risks increase.
3. Does redundancy cost a lot to implement?
It can cost more at the start because you need extra hardware and links. But it usually saves money long-term by preventing expensive outages.
PM Networking is an emerging leader in the ed-tech space, founded by Praphul Mishra in 2020 with a vision to democratize tech education. The journey of PM Networking began as a YouTube channel with the sole purpose of sharing valuable knowledge in the fields of Networking, Cyber Security, and Cloud Computing. What started as a humble effort to educate has rapidly evolved into a comprehensive online learning platform that caters to the growing demand for specialized IT skills. PM Networking stands out in the crowded ed-tech industry by providing affordable, world-class training tailored to the needs of aspiring IT professionals. The platform is dedicated to equipping learners with the skills and knowledge required to excel in the highly competitive tech industry. Whether it’s Networking fundamentals, advanced Cyber Security protocols, or mastering the complexities of Cloud Computing, PM Networking offers a range of courses designed to cater to different levels of expertise.
0 Comments